背景
下半年开始搞精准测试了,先搞一波代码覆盖率,因为公司绝大多数项目都是基于 Java 开发的,所以就先搞 Java 的了,主流的代码覆盖率工具是 Jacoco(其实我也只知道这一个),所以就直接基于 springboot 搞一个吧。
代码覆盖率知识
什么是代码覆盖率
代码覆盖率(Code Coverage)是软件测试中一种衡量测试质量的指标,用于评估测试用例对源代码的覆盖程度。它衡量了在执行测试用例时源代码中有多少行、分支、类、方法等被执行到。
无论是单元测试、API测试还是功能性测试,最终都是调用了产品的代码;如何评价这些测试的效率?这些测试是否真正全部或者大部分覆盖了产品的代码?这个时候,代码覆盖率就是一个比较有价值的参考指标了。
不同的代码覆盖率工具衡量指标可能不同。对于java语言,主流的代码覆盖率工具为Jacoco。当然,Jacoco其实是支持收集运行在JVM上的应用程序的覆盖率的。
代码覆盖率的意义
- 测试视角:分析未覆盖部分的代码,从而反推在前期测试设计是否充分?没有覆盖到的代码是否是测试设计的盲点,为什么没有考虑到?是需求/设计不够清晰,测试设计的理解有误?还是工程方法应用后造成的策略性放弃等等,方便之后进行测试用例设计补充。
- 开发视角:检测出程序中的废代码,可以逆向反推在代码设计中思维混乱点,提醒设计/开发人员理清代码逻辑关系,提升代码质量。
- 其他视角:代码覆盖率高不能说明代码质量高,但是反过来看,代码覆盖率低,代码质量不会高到哪里去,可以作为测试/开发自我审视的重要工具之一。
以上是代码覆盖率正面的意义,但是要注意一点:从质量的角度来说,肯定是希望用例能够对代码全部进行覆盖的,但是从实际出发,进行全覆盖也是不现实的,并且把测试覆盖率作为质量目标没有任何意义,而我们应该把它作为一种发现未被测试覆盖的代码的手段。从现有的覆盖率检测工具来看,即使覆盖率到达了100%,也不能保证用户场景完全被覆盖到或者不会出现漏测,因为从原理上来讲,代码覆盖率只能表示开发写的代码都执行了,但是不表示代码没有逻辑问题,如漏写异常处理,没有完全覆盖用户场景等。
代码覆盖率生成原理
Jacoco代码覆盖率生成主要由以下几个过程组成:
1.代码插桩
插桩分为编译期插桩和运行期插桩,两者区别如下:
- 编译期插桩(Offline模式):在java源文件编译时,直接将桩插入代码行,编译后的class中已经包含了插桩代码,比如使用jacoco-maven-plugin插件即可实现编译期插桩。在Offline模式下,覆盖率数据是通过在编译期对字节码进行插桩生成的文件进行收集和分析。在编译阶段,Jacoco通过在Java字节码中插入代码来记录覆盖率信息。然后,在运行测试或应用程序之后,Jacoco使用已生成的覆盖率数据文件进行分析,生成相应的报告。由于覆盖率数据是在编译期收集并存储在文件中,这种模式可以在任何时候进行分析并生成报告,无需实时地收集覆盖率数据。这对于持续集成和定期报告生成非常有用。
- 运行期插桩(On-the-fly模式):在应用程序运行期间,通过java agent技术,动态的对class文件做插桩,此类技术使用ASM框架实现,动态的修改了字节码文件。在On-the-fly模式下,覆盖率数据是在运行时实时收集并分析的。在应用程序运行时,Jacoco通过Java Agent技术加载到JVM中,并使用字节码插桩机制动态修改正在执行的字节码,以记录覆盖率信息。在应用程序运行期间,Jacoco会实时收集覆盖率数据并保存在内存中。一旦测试执行完成,覆盖率数据可以立即进行分析和报告。这种模式对于需要实时监控和反馈的场景非常有用,例如在开发过程中查看代码覆盖率。
编译期插桩的优点是不需要在运行时进行字节码的修改,可以更方便地与构建工具(如Maven或Ant)集成,并且不会对运行时性能产生显著的影响。缺点是需要重新编译代码,并且生成的插桩后的字节码会增加项目的大小。
运行期插桩的优点是可以对已经编译的字节码进行插桩,无需重新编译代码。缺点是在每次运行应用程序时都需要加载Jacoco Agent,可能会对应用程序的运行时性能产生一定的影响。
2.覆盖率数据收集
在On-the-fly模式下,覆盖率数据使用jacocoagent.jar来收集,此agent会伴随被测服务一起启动。
jacoco生成的覆盖率数据文件默认为exec格式,覆盖率数据输出方式有以下几种:
- file:JVM 终止时,执行数据将写入属性中指定的文件中destfile。
- tcpserver:代理侦听由address和 port属性指定的 TCP 端口上的传入连接。执行数据写入此 TCP 连接。
- tcpclient:启动时,代理连接到address和port 属性指定的 TCP 端口。执行数据写入此 TCP 连接。
- none:不产生任何输出。
一般对于服务端覆盖率数据收集,我们使用tcpserver模式,即jacocoagent跟着被测服务启动时,同时启动一个tcp端口(默认是6300),后续可以通过jacococli或者其他工具访问6300端口来下载覆盖率数据。
3.覆盖率报告生成
覆盖率数据报告生成需要借助jacococli.jar,先通过cli的dump命令获取覆盖率数据文件(即exec文件),然后通过cli的report命令来生成覆盖率数据报告。
全量覆盖率
适用场景:
- 初次测试:当开始进行测试时,全量代码覆盖率非常有用。它可以确保测试用例覆盖了整个代码库,从而验证代码在各种场景下的正确性和稳定性。
- 重构和优化:在进行重构或性能优化时,全量代码覆盖率可以帮助发现可能引入的新问题,并确保代码的质量和性能未受到不良影响。
- 稳定版本验证:在发布稳定版本之前,全量代码覆盖率可用于验证所有已经修改或新增的功能的测试覆盖程度,以确保发布的版本是经过全面测试的。
- 其他需要全量回归的场景,如:机房迁移,新环境部署…
增量覆盖率
jacoco本身是不支持增量代码覆盖率的,但是可以通过二开或者使用其他的开源工具实现增量覆盖率报告生成。
适用场景:
- 快速迭代测试:在项目快速迭代的情况下,仅针对新增或修改的代码进行增量代码覆盖率分析能够快速确定这些变动的测试覆盖程度,以便加快迭代速度。
- 高频更新验证:对于经常更新的代码库,每次都进行全量代码覆盖率分析可能会产生高昂的计算和执行成本。使用增量代码覆盖率可以更快地了解测试覆盖的变化情况,以便快速验证新增功能的正确性和稳定性。
- 增量测试补充:当时间有限而需求变动时,增量代码覆盖率可用于快速确定需求变动对现有测试覆盖的影响,并有针对性地补充和调整测试用例,以覆盖新增或修改的代码。
建设思路
- 目标:为整个中心不同部门/项目组提供统一的Java 代码覆盖率收集能力
- 前期准备:
- 收集试点项目的技术栈,包括:开发框架,部署架构。
- 了解不同项目组对代码覆盖率的使用场景,比如 TL 关心开发提交的代码是否夹带私货,是否存在 dead code。测试人员或者产品经理关心是否测试全面,想通过代码的变更点推导出业务上的影响面。开发人员关心自己本个迭代提交的代码是否都测试完全等。
- 技术选型:
- 后端开发技术栈:Springboot,JacocoCli,Jgit,MavenCli,GradleToolingApi,MySQL,MyBatis
- 前端开发技术栈:vue2
应用架构设计(业务视角)
业务架构图不方便贴,就说下基本流程:
- 配置凭据,即Git 账号和密码,此处使用类似 Jenkins 凭据的方式来管理。
- 配置服务信息,如服务名称,git 仓库地址,环境类型,dump 端口(jacocoagent启动端口),ip 列表(同一个服务在不同环境有不同 ip,而且可能是多实例部署),选择凭据。
- 配置覆盖率采集任务,选择环境自动带出此环境下面的服务列表,填写任务名称,迭代信息,在选择服务的时候要选择分支,如果是增量覆盖率,则需要选择采集分支和基准分支,如果是全量覆盖率,则选择采集分支即可。
- 执行采集任务,生成执行记录和覆盖率报告。
应用架构设计(技术视角)
代码覆盖率只是整个测试平台的一个服务,测试平台使用 SBA 架构(服务导向的架构),整个平台架构图如下所示:
代码覆盖率量子中只包含一个代码覆盖率容器,配合插件层的 jacocoagent 插件来协同工作。
安全方案
代码覆盖率收集服务,主要业务是:根据用户配置的代码库地址和GIT账密来收集 Java 应用服务在某个时间段内的代码覆盖情况。其中会涉及到用户在平台上填写以下数据:
- 代码库地址(以下简称 代码库)
- GIT账号和密码(以下简称 凭据)
同时生成的覆盖率报告会包含部分/所有的代码信息,因此需要对覆盖率报告也做数据权限的管控。
因为测试平台使用多租户模式,所以不同的租户下面数据是完全隔离的,不存在跨租户访问数据的情况,只需要解决水平越权和垂直越权的安全问题即可。
因为安全方案涉及到公司内部数据,所以只给出以下思路:
- 菜单权限/api权限:可以基于 Spring Security实现,或者其他安全框架实现
- 数据权限:对接口中的入参 by 租户进行校验,不允许访问未授权的测试库数据
- 数据安全:对 GIT 密码进行加密保存,可以选择 DES 或者 RSA 非对称加密
业务流程
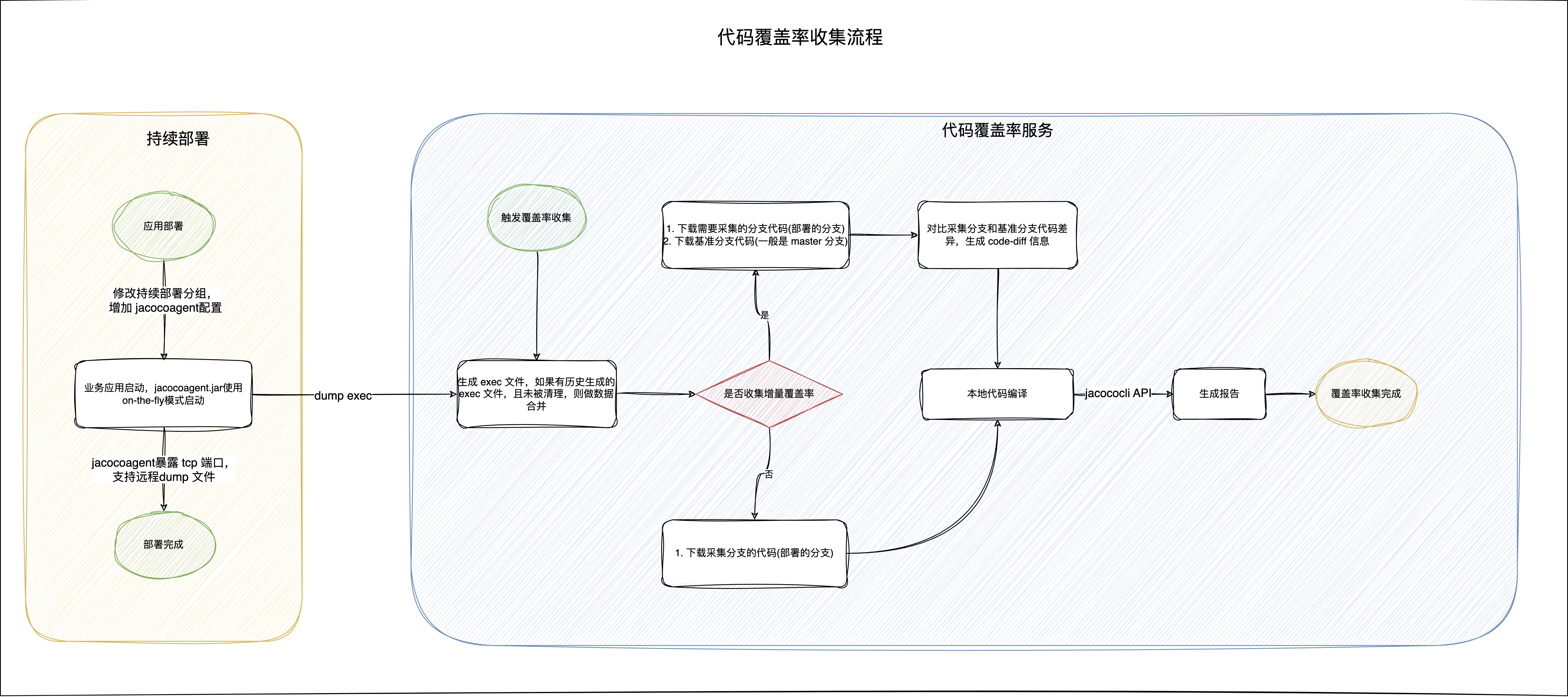
代码覆盖率收集过程
Step-1:代码插桩
代码覆盖率收集过程基于 jacoco 的插桩来实现,jacoco 支持 2 中插桩方式:
On-the-fly 模式(即时模式):
插桩时机:在应用程序运行时,通过 Java 代理(Java Agent)将 JaCoCo 注入到 JVM 中。
数据收集方式:实时地收集代码覆盖率数据,即时生成运行时的覆盖率报告。
优点:
- 可以实时地监测应用程序的执行和覆盖率情况。
- 不需要对代码进行重新编译,使得在现有项目中使用更为方便。
缺点:
- 在运行时对字节码进行修改,可能会对应用程序的性能产生一定影响。
- 数据收集和报告生成过程会占用一些 CPU 和内存资源。
Offline 模式(离线模式):
插桩时机:在构建过程中对项目的字节码进行修改,通过构建工具(如 Maven 或 Gradle)进行插桩。
数据收集方式:在应用程序运行时,JaCoCo 会收集覆盖率数据并将其保存到执行文件中(通常是一个二进制格式的 .exec 文件)。
优点:
- 不会对应用程序的运行性能造成直接影响。
- 可以在构建过程中自动插桩,方便集成到自动化构建和持续集成流程中。
缺点:
- 需要对项目进行重新编译,可能会增加构建过程的时间和开销。
- 需要对执行文件进行处理,生成可读性更好的覆盖率报告。
Step-2:生成 exec 文件
exec 文件是 jacoco 默认的覆盖率数据文件类型,使用 on-the-fly 模式时,可以通过 Socket连接的方式,从远程服务器(即部署了 jacocoagent 的服务器) 上下载 exec 文件。JaCoCo 生成的 exec 文件是二进制文件,其中包含了代码覆盖率数据。它的结构如下:
Header(文件头部):包含了 exec 文件的元数据信息,如版本号和会话标识符。
Sessions(会话信息):存储了测试会话的信息,每个会话都有一个唯一的会话标识符。
Probes(探针信息):存储了所有被覆盖的代码块的信息。每个代码块都有一个唯一的标识符,并且将内联代码的情况进行了处理。
Execution Data(执行数据):实际的代码覆盖率数据。它记录了每个代码块是否被执行过。
具体来说,Header 部分包括以下信息:
Magic Number:一个特殊的标识符,用于识别文件类型。
Version:exec 文件的版本号。
Session Count:会话数量。
Session Infos:会话信息的起始位置。
Probe Count:探针数量。
Probe Infos:探针信息的起始位置。
Sessions 部分包括了每个会话的信息,例如会话标识符和会话名称。
Probes 部分包括了每个被覆盖的代码块的信息,例如代码块的标识符和分支相关的信息。
Execution Data 部分包括了实际的代码覆盖率数据,记录了每个代码块是否被执行过。
Step-3:代码差异比对(增量覆盖率才有此步骤)
code-diff 阶段用于比对代码差异,进而分析出代码变更点。代码变更包括以下几种情况:
新增,修改,删除不会被统计在内,因为文件已经被删除,不会产生覆盖率数据。如果是全量覆盖率报告生成,则会跳过此阶段。code-diff 功能使用 jgit 库和 javaparser 库的 API 实现。code-diff 流程如下:
下载采集分支代码,即新分支,如 feature,develop 等。
下载基准分支代码,即需要与之比较的分支,一般是 master 或者 release 等稳定分支。
使用 jgit 获取变更过得文件,即 java 源文件。
使用 javaparser 获取变更的类和方法,并记录方法信息(方法名,包名,方法签名等)。
生成 code-diff文件,用于后面生成增量报告。
Step-4:代码编译
代码编译过程用于将 java 源代码编译成 class 文件,用于生成覆盖率报告,在生成 JaCoCo 报告时,需要使用 class 文件和源码文件主要是为了对覆盖率数据进行解析和展示。
Class 文件:JaCoCo 通过分析 class 文件来获取代码结构和字节码信息。它包含了类、方法和字段的定义、修饰符以及字节码指令等信息。通过分析 class 文件,JaCoCo 可以确定每个代码块(如行、分支等)的起始和结束位置。
源码文件:源码文件是编写程序的原始文件,其中包含了开发人员编写的代码。在生成覆盖率报告时,JaCoCo 将覆盖率数据与源码文件进行关联,并进行代码染色,以显示被执行和未执行的代码行。这样,开发人员可以清楚地看到哪些行被覆盖,哪些行未被覆盖。本服务支持 Gradle 项目和 maven 项目编译,编译工具版本如下:
- JDK:jdk11,jdk8
- Gradle:gradle 7, gradle 6, gradle 5
- Maven:maven 3.6.1
Step-5:报告生成
支持增量报告和全量报告生成。增量报告用于比较不同版本之间代码差异和覆盖率情况,全量报告直接展示新版本代码覆盖率情况。两种报告使用场景如下:
增量报告:
- 新迭代差异代码覆盖情况,一般用于开发自测,检查变更的代码是否被执行
全量报告:
- SIT 测试,通过代码覆盖情况间接表示功能覆盖情况
- 全量回归测试,比如机房迁移,项目重构等,会统计此分支下所有代码的执行情况
技术方案
代码同步
直接使用 Jgit 即可,Maven 坐标如下:
1 | <dependency> |
示例代码如下:
1 | public String clone(String repoUrl, String branch, String localPath, String username, String password) { |
代码编译
Maven 项目编译
Maven 项目使用 Maven embedder 进行编译
Maven 坐标如下
1 | <dependency> |
示例代码如下:
1 |
|
1 | public class MavenCommand { |
Gradle 项目编译
Gradle 项目使用 gradle tooling api进行编译
Maven 坐标如下:
1 | <dependency> |
示例代码如下:
1 |
|
1 | public class GradleCommand { |
差异代码比对
直接参考这个就好:https://gitee.com/Dray/code-diff/blob/master/src/main/java/com/dr/code/diff/service/impl/CodeDiffServiceImpl.java
原理就是直接通过jgit 分析出变更的文件,然后通过 javaparser 来分析代码
覆盖率报告生成
生成报告参考这个:https://gitee.com/Dray/code-diff/blob/master/src/main/java/com/dr/code/diff/jacoco/report/ReportAction.java
但是里面涉及到差异报告生成,就需要使用这个仓库提供的 jar 了
覆盖率报告解读
全量覆盖率报告
报告总览
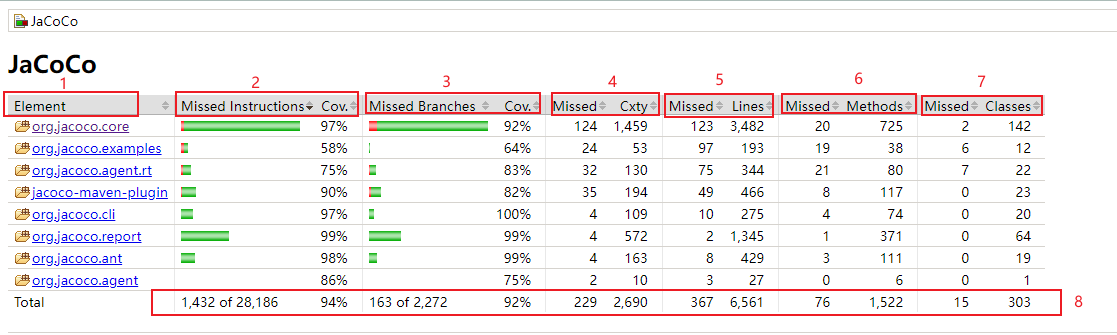
- Element:被覆盖和测量的代码元素,通常是源代码的各种层级,比如 模块,包,类,方法。其实在jacoco的报告中,也是按照上面的层级逐步深入展示覆盖率报告的。
- Instructions:指令覆盖,Java 字节指令的覆盖率。执行的最小单位,和代码的格式无关。
- Branches:分支覆盖,如if分支,switch分支等。
- Cxty:圈复杂度,Jacoco 会为每一个非抽象方法计算圈复杂度,并为类,包以及组(groups)计算复杂度。圈复杂度简单地说就是为了覆盖所有路径,所需要执行单元测试数量,圈复杂度大说明程序代码可能质量低且难于测试和维护。
- Lines:行覆盖,只要本行有一条指令被执行,则本行则被标记为被执行。
- Methods:方法覆盖,任何非抽象的方法,只要有一条指令被执行,则该方法就会被计为被执行。
- Classes:类覆盖,所有类,包括接口,只要其中有一个方法被执行,则标记为被执行。注意:构造函数和静态初始化块也算作方法。
- 覆盖率数据:注意,上图中 1432 of 28186 94% 表示的意思是 一共有28186条指令,其中有1432条指令没有执行,94%≈(28186-1432)/28186 * 100%
背景色及标记
由于单行通常编译为多个字节代码指令,源代码突出显示为包含源代码的每行显示三种不同的状态
背景色:
- 无覆盖:该行没有指令被执行(红色背景)
- 部分覆盖:仅执行了该行的部分指令(黄色背景)
- 全覆盖:该行所有指令均已执行(绿色背景)
菱形标记:
- 绿色菱形:这一行的所有分支都被执行
- 黄色菱形:这一行的分支中只有一部分被执行
- 红色菱形:在这一行中没有分支被执行

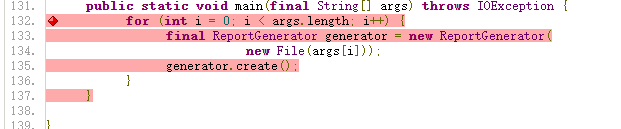
增量覆盖率报告
增量覆盖率报告与全量覆盖率报告大体一致,只有部分标记存在差异。
- 蓝色加号:新增的代码
- 黄色铅笔:修改过的代码
代码覆盖率接入常见问题
jacoco官方本身提供了FA&Q,绝大多数覆盖率相关的问题都可以在这边找到,只有以下比较特殊的场景需要注意:
反射导致的服务启动失败或者接口调用失败
jacoco不管是以何种方式运行,都会在class中插入static boolean[] $jacocoData 和 $jacocoInit() 来记录覆盖率数据。当我们使用反射来获取一个类的属性和方法时,很容易就获取到这两个特殊的Field,比如通过一个类来保存JDBC配置的时候,就会读到$jacocoData,导致jdbc连接失败。为了解决这个问题,需要在使用反射的地方通过如下方法处理:
1 | public static void main(String[] args) { |
关于 isSynthetic() 的解释可以参考:Class.IsSynthetic 属性 (Java.Lang)
写在最后的话
准备提桶了,没啥心情写了,就先写这么多吧,希望诸位都能找到合适的工作
PS:代码编译比较耗费资源,记得改成 mq,触发任务采集的时候通过 mq 来做任务排队
参考文档
- https://www.jacoco.org/jacoco/trunk/doc/
- https://gitee.com/Dray/jacoco
- https://gitee.com/Dray/code-diff
- https://blog.csdn.net/Huang1178387848/article/details/114399056
- https://maven.apache.org/ref/3-LATEST/maven-embedder/index.html
- https://blog.csdn.net/ByteDanceTech/article/details/123059368
- https://www.jacoco.org/jacoco/trunk/doc/mission.html
- https://www.jacoco.org/jacoco/trunk/doc/counters.html
- https://www.jacoco.org/jacoco/trunk/doc/agent.html
- https://www.jacoco.org/jacoco/trunk/doc/cli.html
- https://www.jacoco.org/jacoco/trunk/doc/faq.html
- https://blog.csdn.net/tushuping/article/details/134347325
- https://blog.csdn.net/tushuping/article/details/112613528
- https://blog.csdn.net/tushuping/article/details/131640959